
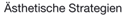
Zunächst sollte man sich verdeutlichen, welche Datenmengen bei der Digitalisierung von Musik anfallen.
Eine Sekunde Stereo Signal entspricht:
| 44,1 kHz | 22 kHz | 11 kHz | |
| 16 Bit | 176 KByte/s 1.411 KBit/s |
88 KByte/s 704 KBit/s |
44 KByte/s 352 KBit/s |
| 12 Bit | 132 KByte/s 1.058 KBit/s |
66 KByte/s 528 KBit/s |
33 KByte/s 264 KBit/s |
| 8 Bit | 88 KByte/s 705 KBit/s |
44 KByte/s 352 KBit/s |
22 KByte/s 176 KBit/s |
Ein Stück mit 3,40 Min in CD-Qualität (44,1 kHz/16 Bit) umfaßt beispielsweise rund 38 MB. Für eine Einbindung in Multimedia- oder Internetanwendungen ist diese Datenmenge nicht praktikabel.
Es ist demnach notwendig, den Umfang der Audiodaten zu reduzieren. Eine Reduktion durch Herabsetzen von Samplingfrequenz und -auflösung (wie in obiger Tabelle zu ersehen) führt zu unerwünschten Nebeneffekten (Abtasttheorem, Quantisierungsrauschen).
Auch durch einen der herkömmlichen nondestruktiven Datenkomprimierungsalgorithmen (Zip, Lharc, Rar, etc.), läßt sich aufgrund der komplexen Strukturen von Audiodaten meist nur eine Reduktion um 5-20% erreichen. Daher wurden für die Speicherung und Ubertragung von Audiosignalen spezielle Verfahren entwickelt.
Die verlustlose Datenkompression basiert auf Verfahren der linearen Prädiktion mit nachfolgender Entropiecodierung.
Bei der linearen Prädiktion wird für einem Block von Abtastwerten ein Koeffizientensatz bestimmt, auf dessen Grundlage eine Schätzung der Folge der Abtastwerte (Amplitudenverlauf) erfolgt. Je genauer die Schätzung mit dem tatsächlichen Verlauf übereinstimmt, desto geringer ist die Amplitude des Differenzsignals.
Bei der Entropiecodierung wird dann das Differenzsignal in Abhängigkeit von der Verteilungsdichtefunktion des Blocks quantisiert. Abtastwerten mit großer Häufigkeit werden mit kurzen Datenworten, Abtastwerten mit geringer Häufigkeit werden mit längeren Datenworten codiert.
Schließlich wird aus dem bestimmten Koeffizientensatz und dem entropiecodierten Differenzsignal ein Rahmen gebildet, der alle Informationen für die Decodierung beinhaltet.
Die dadurch ereichbaren mittleren Kompressionsraten erlauben in Abhängigkeit von der Statistik des Audiosignals eine Datenreduktion bis 50%.
Verlustbehaftete Codierungsverfahren ermöglichen unter Ausnutzung psychoakustischer Phänomene wesentlich höhere Kompressionsraten. Allerdings ist die Nachbearbeitung bereits komprimierter Signale sowie die mehrfache Codierung/Decodierung mit zusätzlichen Problemen behaftet.
Diese Codierungsverfahren basieren meist auf folgenden Einzelschritten:
Beispiel MP3 (nach Wikipedia)
Die Ergebnisse psychoakustischer Untersuchungen von Zwicker bilden die Grundlage zur gehörangepaßten Codierung (Perceptual Coding) von Musiksignalen. Das menschliche Gehör analysiert breitbandige Schallereignisse in sogenannten Frequenzgruppen. Bei der psychoakustischen Codierung wird das Audiosignal anhand der Frequenzgruppen zerlegt und die resultierenden Teilbänder unter Berücksichtigung der absoluten Hörschwelle und von Verdeckungseffekten codiert
Die absolute Hörschwelle ist der Verlauf des Schalldruckpegels in Abhängigkeit von der Frequenz, unterhalb derer keine Signale wahrgenommen werden können.
Als Verdeckungseffekt wird die Eigenschaft des menschlichen Gehörs bezeichnet, einer Frequenz mit hohem Pegel benachbarte Frequenzen mit niedrigerem Pegel nicht wahrzunehmen.
Erklingt beispielsweise ein Ton mit 440 Hz bei einer Lautstärke von 60 dB, bleiben in seinem Band alle anderen Frequenzen die leiser als 35 dB sind - also auch das Rauschen - unhörbar. Der notwendige Rauschabstand beträgt demnach nur noch 25 dB und dafür reichen 4 Bit Auflösung aus.
Das Akronym MPEG steht für "Motion Pictures Experts Group". Man bezeichnet damit eine von der International Standards Organization (ISO) und der International Electro-Technical Commission (IEC) anerkannte Sammlung von standardisierten Verfahren und Formaten im digitalen Video- und Audiobereich.
MPEG-1 Audio definiert u.a. drei Coder/Decoder, die als Layer I-III bezeichnet werden. Die Algorithmen sind hierarchisch kompatibel, wodurch der Decoder des Layer n in der Lage ist, Signale des Layer n und der darunter zu dekodieren. Die Komplexität der Coder und Decoder steigt mit der Ziffer des Layer, womit eine bessere Qualität bei erhötem Rechenaufwand erreicht wird. Die Bitraten des Ausgangssignals sind auf 32, 44.1 und 48 kHz begränzt.
Layer I
Zur Informationsseite des Fraunhofer IIS (MPEG1 Layer 3)
Das Layer III Verfahren hat in den letzten Jahren enorm an Bedeutung gewonnen. Es wurde ab 1987 vom EUREKA Projekt EU147 "Digital Audio Broadcasting (DAB)" entwickelt. Entscheidend war dabei die Arbeit der Universität Erlangen (Prof. Dieter Seitzer, Frauenhofer Gesellschaft). Die Qualität ist bei einer Bitrate von unter 128 KBit/s so hoch, daß es beim MoD-Dienst der Telekom und für die DVD (Europa) angewandt wird.
Typische Performance Daten von MPEG-1/2 Layer III:
| Subjektive Quality | Bandbreite | Mode | Bitrate | Kompression |
| "telephone sound" | 2.5 kHz | mono | 8 Kbps*) | 96:1 |
| "Besser als Kurzwelle" | 4.5 kHz | mono | 16 kbps | 48:1 |
| "Besser als Mittlewelle" | 7.5 kHz | mono | 32 Kbps | 24:1 |
| "Ähnlich wie UKW" | 11 kHz | stereo | 56...64 Kbps | 26...24:1 |
| "CD nahe" | 15 kHz | stereo | 96 Kbps | 16:1 |
| "CD nahe" | 15 kHz | stereo | 112..128 Kbps (128Kbps: Internetstandard) |
14..12:1 |
| "CD" | 15 kHz | stereo | ab 160 Kbps | 10:1 |
| (* Mpeg 2.5 Erweiterung der Frauenhofer Gesellschaft) | ||||
Kodierungsmodell MP3:
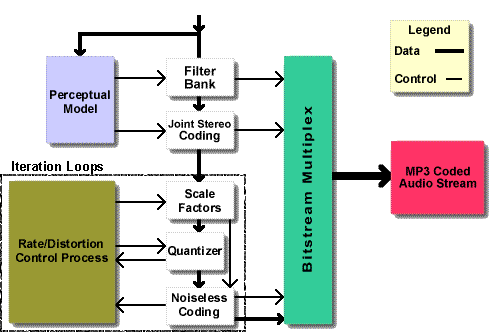
Quelle: http://www.iis.fraunhofer.de/amm/techinf/layer3/index.html
MPEG-2 Audio arbeitet wie MPEG-1 mit den gleichen Layern. Zusätzliche Erweiterungen:
Neben den MPEG-Layern gibt es noch eine Reihe weiterer Kompressionsverfahren wie Vorbis oder Windows Media Audio. Siehe hierzu z.B.: c't-Magazin für Computertechnik, Heft 19/2002, S. 94-109.
Für den Audio-Konsumerbereich sind hier zwei Spezifikationen interessant:
Als Streaming bezeichnet man Datenübertragungsverfahren, bei denen die Wiedergabe der übertragenen Dateien bereits während der Übertragung erfolgt. Auch bei Mp3-Dateien ist ein Abspielen während des Downloads möglich, Vor/Zurückspulen, Anpassung der Qualität an die zur Verfügung stehende Bandbreite sind allerdings nur durch spezifiische Client/Server-Technik möglich.
Bei der Bandwidth Negotiation werden zwischen Server und Client ständig Daten über die momentane Datenübertragungsrate ausgetauscht, um bei anhaltend zu niedrigen Übertragungsraten auf eine Datei auszuweichen, für die die momentane Verbindungsqualität ausreicht.
Im Gegensatz zu den meisten anderen Dateien (Texte, Programmdateien, etc.), hat die Vollständigkeit der Übertragung bei den Multimediainhalten Audio/Bild/Bewegtbild eine geringere Bedeutung. Einzelne Inkonsistenzen können durch geschickte Interpolation verdeckt werden.
Die Anforderung eines Mutlimediaclips durch den RealPlayer geschieht durch eine bidirektionale TCP-Verbindung (Transmission Control Protocol). Die Multimediadaten werden dann auf einem schnelleren UDP-Kanal (User Datagram Protocol) vom Server gesendet. UDP setzt wie TCP auf IP (Internet Protocol) auf, gewährleistet allerdings keine Verifikation der Vollständigkeit einer Übertragung. Pakete, die überhaupt nicht oder nicht rechtzeitig beim Player ankommen, werden interpoliert. Zur Steuerung des Multimedia-Streams bleibt die TCP/IP Verbindung zwischen Client (RealPlayer) und dem RealServer erhalten.
Sieht man von Real Audio, das ein wenig in die Jahre gekommen ist, und Ogg Vorbis, das wir als Open Source Projekt mit hoffentlich zunehmender Verbreitung unterstützen, ab, so haben sich für die Musikdistribution im Internet zur Zeit folgende Formate durchgesetzt:
Verfahren digitaler Audiobearbeitung
62006 Großmann | WS 07/08
S | 1-4 | B2 | Di 14.15-15.45 | C 7.215 UC
Tutorium | Donnerstag 13.00 - 14.00 | 7.212 UC
Quelle: http://audio.uni-lueneburg.de/seminarwebseiten/sequenzing-neusite12.php, 06.07.2026